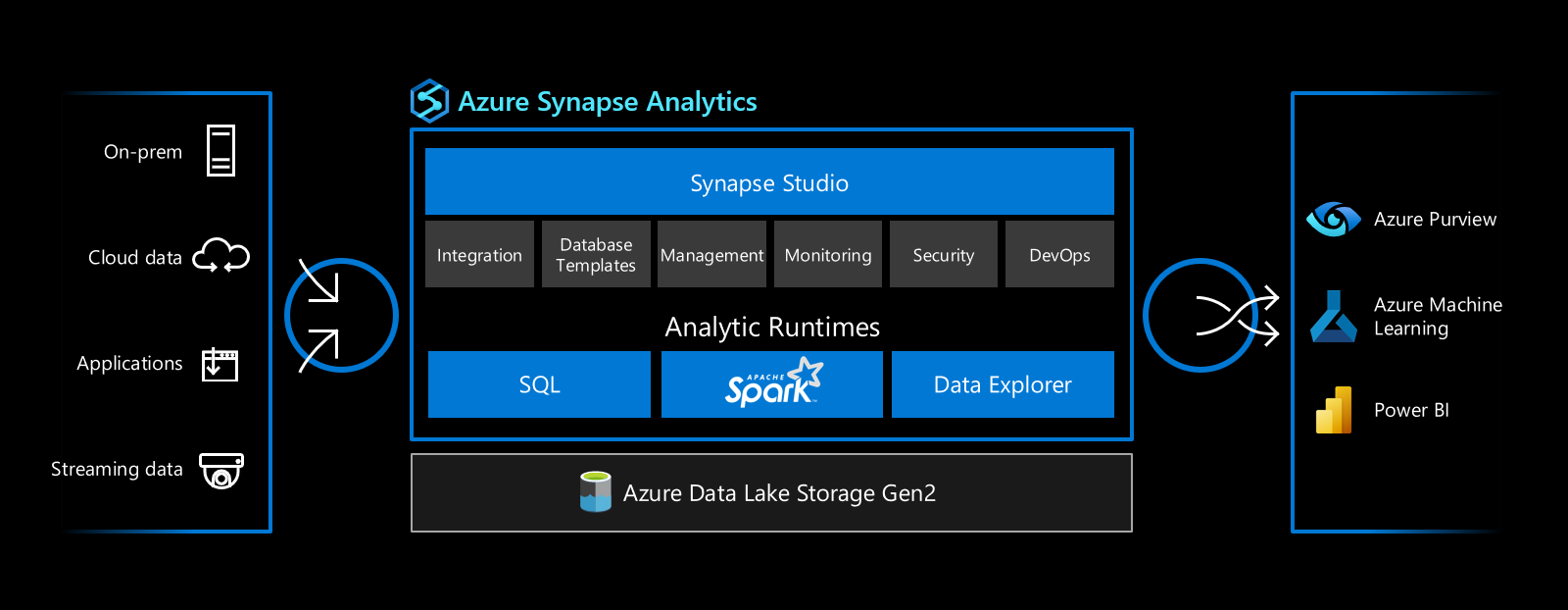
Azure Synapse Analytics
/Harnessing the ability to ingest, explore, prepare, transform, and serve data, historically meant that customers needed to provision, configure, and maintain, multiple services suited to the different stages of the data lifecycle. Within the Microsoft ecosystem and prior to the availability of Azure Synapse Analytics, the usual suspects that would help facilitate such a set of capabilities would include services such as Azure Data Factory for data integration, Azure Databricks for big data, and dedicated SQL pools (formerly SQL DW) for data warehousing. With Azure Synapse Analytics, Microsoft has unified these capabilities under a single analytics service.
Features:
Unified Analytics Platform - With Synapse Studio, users have a single pane of glass to ingest, explore, prepare, transform, and serve data.
Heterogeneous Analytic Runtimes - Synapse SQL for data warehousing, Apache Spark for big data, and Data Explorer for log and time series analytics.
Built-In Data Integration - Based on the data integration capabilities found in Azure Data Factory, with support for 100+ native connectors. Note: There are some feature differences between the two engines.
Flexible Consumption Models - Support for both serverless and dedicated SQL pools allows users to choose the most cost-effective pricing option for each workload.
Cloud-native HTAP - With Azure Synapse Link, get near real-time insights from data sources such as Azure Cosmos DB and Dataverse without impacting the performance of source systems and no ETL jobs to manage.
History
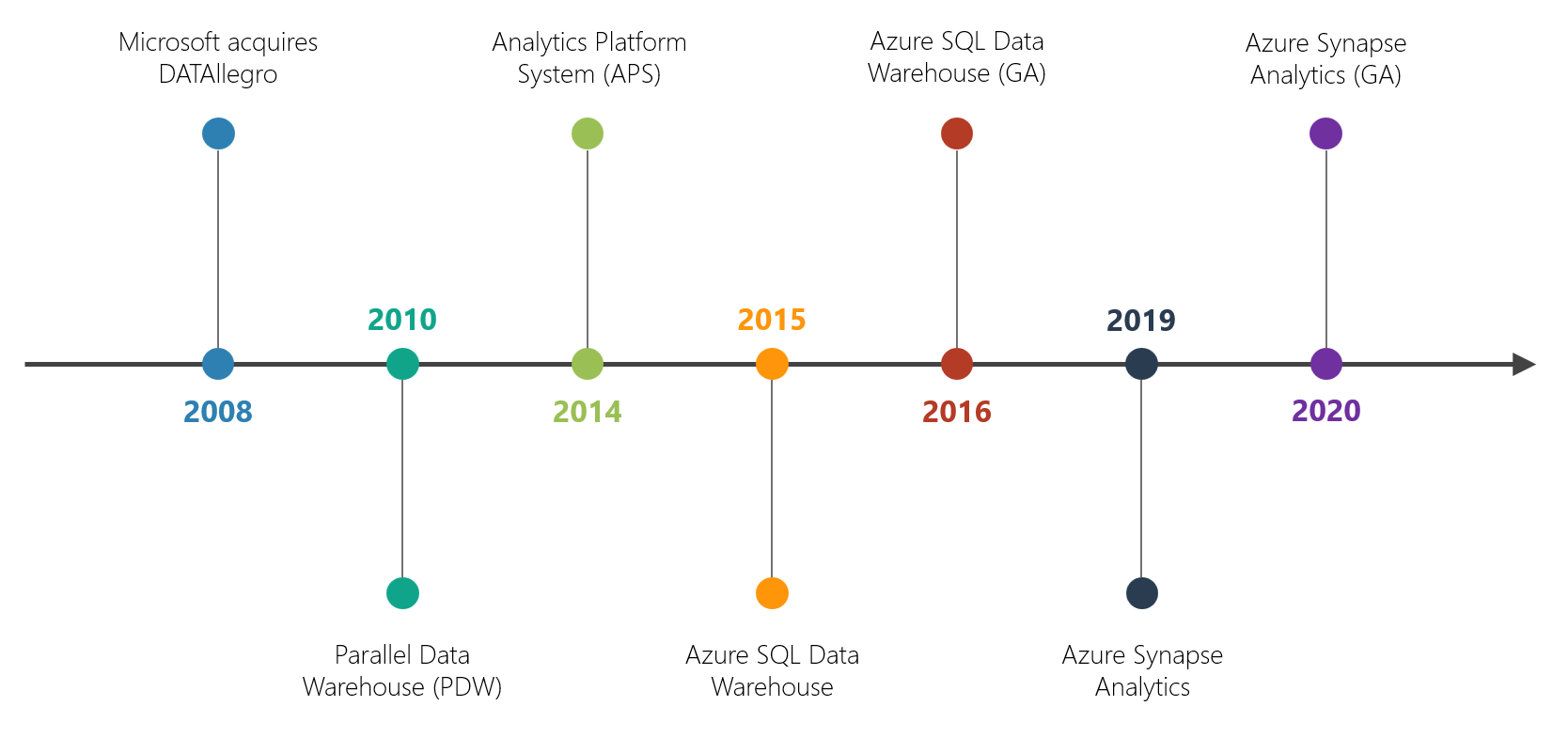
To attain a better understanding of the Azure Synapse Analytics service, it can help to acknowledge the journey Microsoft’s analytics platform has gone through.
2008 - Microsoft acquires DATAllegro, a provider of data warehouse appliances.
2010 - Microsoft announces SQL Server 2008 R2 Parallel Data Warehouse (aka Project Madison), an enterprise data warehouse appliance based on the massively parallel processing (MPP) technology originally created by DATAllegro.
2014 - Microsoft announces the Analytics Platform System (big data in a box), an evolution of the SQL Server Parallel Data Warehouse with the introduction of a dedicated region for Microsoft’s Hadoop distribution - HDInsight. Using PolyBase (Microsoft’s SQL Server to HDFS bridge technology), customers could join relational data from SQL Server PDW and non-relational data in Hadoop.
2015 - Microsoft announces Azure SQL Data Warehouse, an elastic data warehouse in the cloud. Allows customers to dynamically scale (grow and shrink) and pause compute, independent of storage.
2016 - Microsoft announces the general availability of Azure SQL Data Warehouse. Offers an availability SLA of 99.9%.
2019 - Microsoft announces Azure Synapse Analytics, the next evolution of Azure SQL Data Warehouse. Includes the addition of new preview capabilities such as workload isolation, on-demand query (aka serverless SQL), Azure Synapse Studio, and Apache Spark integration.
2020 - Microsoft announces the general availability of Azure Synapse Analytics.
2021 - Microsoft announces the public preview of Azure Synapse Data Explorer, complementing the existing Synapse SQL and Apache Spark analytic engines.
Synapse Studio
Synapse Studio is a web-based portal which enables users to perform a variety of data engineering and analytic based tasks (ingest, explore, prepare, visualize), monitor activity and usage, and manage the entire platform, all within a single user experience.

Home
The Home Hub is the initial landing page which contains links and resources to help you get started quickly.

Data
The Data Hub is where you can create, view, and interact with data sources and datasets. Within the Data Hub, there are two tabs - Workspace and Linked. The Workspace tab contains a list of databases of which there are currently three types - Lake (previously known as Spark databases), SQL (Serverless or Dedicated), and Data Explorer. The Linked tab contains a list of External Data (subset of Linked Services which Synapse is able to provide an enhanced user experience with native Action buttons) and Integration Datasets which can be used in pipeline activities and data flows.

Develop
The Develop Hub is where you can create Synapse artifacts to query, analyse, and model data in a code or code-free manner. Supported objects include SQL scripts, KQL scripts, Notebooks (Python, Scala, .NET - C#, and Spark SQL), Data flows (data flow or flowlet), and Apache Spark job definitions (Python, Scala, .NET - C#/F#).

Integrate
The Integrate Hub is where you can create Synapse pipelines which can be used to orchestrate the movement and transformation of data through the logical grouping of activities (Data Movement, Data Transformation, or Control Flow).

Monitor
The Monitor Hub is where you can view the status and properties of Analytics Pools (SQL, Apache Spark, or Data Explorer), Activities (SQL requests, KQL requests, Apache Spark applications, or Data Flow debug sessions), and Integration components such as Runs (Pipeline or Trigger) or Integration Runtimes.

Manage
The Manage Hub is where you can create and manage, Analytics pools (SQL, Apache Spark, or Data Explorer), External connections (Linked Services or Azure Purview), Integration (Triggers or Integration Runtimes), Security (Access control, Credentials, Managed private endpoints), Code libraries (Workspace packages), and Source control (Git configuration).
Concepts
Analytics Pools
SQL Pool - Serverless
Every Azure Synapse Analytics workspace comes with a serverless SQL pool endpoint which allows you to query files in Azure Storage accounts and Azure Cosmos DB. Scaling is done automatically. No need to reserve capacity. Billing is based on the amount of data processed (pay-per-query model). Scenarios include basic discovery and exploration, facilitating a logical data warehouse, and data transformation.SQL Pool - Dedicated
Dedicated SQL pools (formerly known as SQL DW) represent a collection of resources (CPU, memory, and IO) that leverages a scale-out architecture to distribute computational processing of data across multiple nodes (parallel processing). In contrast to serverless which is built-in and scales automatically, dedicated SQL pools need to be provisioned, with each unit of scale measured in Data Warehouse Units (DWUs), an abstracted measure of compute resources and performance. With decoupled storage and compute, these components can be sized independently and therefore are billed separately. Ideal for high-performance analytic workloads that require consistent compute requirements.Apache Spark Pool
Apache Spark is a parallel processing engine that is highly suited to big data and machine learning. Apache Spark pools in Azure Synapse Analytics is one of Microsoft’s implementations of Apache Spark. An Apache Spark pool is serverless and therefore exists only as metadata (i.e. definition only). When you connect to a Spark pool, for example via a notebook, it is at this point that a session is created, and resources are consumed. Multiple users can access the same Spark pool definition, with a new Spark pool instance created for each user.Data Explorer Pool
Data Explorer is an analytical engine optimized for near real-time log and time series analytics, with the ability to automatically index unstructured (free text) and semi-structured (JSON) data. When using Azure Synapse Data Explorer, compute and storage are decoupled, which allows you to scale compute and storage independently.
Workspace
SQL Database
There are two types of SQL databases that can be created within an Azure Synapse Analytics workspace - Serverless or Dedicated. In the context of serverless, while the default master database is immediately available, ideal for simple data exploration scenarios, you may want to create a separate serverless SQL database to logically group utility objects such as external tables/data sources/file formats/etc. When it comes to dedicated SQL pools, a database of the same name is automatically created upon provisioning the dedicated SQL pool itself.Lake Database
Lake Database (previously known as Spark Database) have two key characteristics: Tables in Lake Databases keep their underlying data in Azure Storage accounts (i.e. Data Lake) and Tables in Lake Databases are exposed and can be queried by Serverless SQL Pools or Apache Spark Pools.Data Explorer Database
Once a Data Explorer Pool is provisioned and running, we can create one or more Data Explorer Databases to logically group utility objects such as Tables, Views, and Functions.
Develop
SQL script
A SQL script contains one or more SQL commands. Azure Synapse Analytics natively supports SQL scripts as an artifact which can be created, authored, and run directly within Synapse Studio. The SQL editor within Synapse Studio features IntelliSense which can help expedite code completion and can also export SQL scripts locally to a file with the .sql file extension.KQL script
KQL stands for Kusto Query Language and is used to express logic to query data that resides within a Data Explorer database. Similar to SQL scripts, KQL scripts contain one or more KQL commands. Azure Synapse Analytics natively supports KQL scripts as an artifact which can be created, authored, and run directly within Synapse Studio.Notebook
A Notebook consists of cells, which are individual blocks of code that can be run independently (one at a time) or as a group (sequentially). Notebooks are commonly used in data preparation, data visualization, machine learning, and other big data scenarios.Data flow
Data flows allow data engineers to express transformation logic without writing code (visual experience). Data flows are executed as activities within an Azure Synapse Analytics pipeline and leverage Apache Spark clusters as the underlying compute.Apache Spark job definition
An Apache Spark job definition can be created as an artifact within Azure Synapse Analytics and contains a reference to packaged Spark code (Python/.py, Scala/.jar, or .NET/.zip). Once created, you can submit an Apache Spark job definition to an Apache Spark pool to run as a batch job. Alternatively, an Apache Spark job definition can be incorporated as an activity within an Azure Synapse Analytics pipeline.
Integration
Linked Service
In order to establish a connection between Azure Synapse Analytics and external resources, we need to first create a Linked Service object which encapsulates the connection details. For example, establishing a connection to an Azure Data Lake Storage Gen2 account will require a Linked Service which will hold details such as Name, Description, Connection Method (e.g. Integration Runtime), Authentication Method (e.g. Account Key), and so on.Integration Dataset
An Integration Dataset is simply a named reference to data that can be used in an activity as an input or output. All Integration Datasets belong to a Linked Service.Pipeline
A Pipeline is a logical grouping of activities that together perform a task (e.g. ETL or ELT). For example, you may create a pipeline that includes a copy activity to copy data from SQL Server to Azure Blob Storage.Trigger
The concept of executing a pipeline to run is based on Triggers. To run a pipeline on-demand (i.e. immediately), this is referred to as a manual trigger. Alternatively, we can instantiate specific types of Trigger objects and associate those to one or more pipelines. Azure Synapse Analytics supports the following types of triggers: Schedule, Tumbling Window, Storage Events, and Custom Events.Integration Runtime
Integration Runtime is the compute infrastructure used by Azure Synapse pipelines to provide data integration capabilities across different network environments. Azure Synapse Analytics currently supports two types of Integration Runtime: Azure or Self-Hosted. Note: Azure Synapse Analytics currently does not support the Azure-SSIS runtime used to execute SSIS packages.
Resources
This blog post provides a high-level overview of the spectrum of capabilities offered within the Azure Synapse Analytics platform and context behind some of the key concepts. For more information, check out the resources below.