Getting Started with Apache Spark
/What is Apache Spark?
Apache Spark is a unified analytics engine for big data processing and machine learning. In contrast to other systems which require separate engines for different analytical workloads, Spark supports code reuse across batch processing, interactive ad-hoc queries (Spark SQL), real-time analytics (Spark Streaming), machine learning (MLib) and graph processing (GraphX).
History
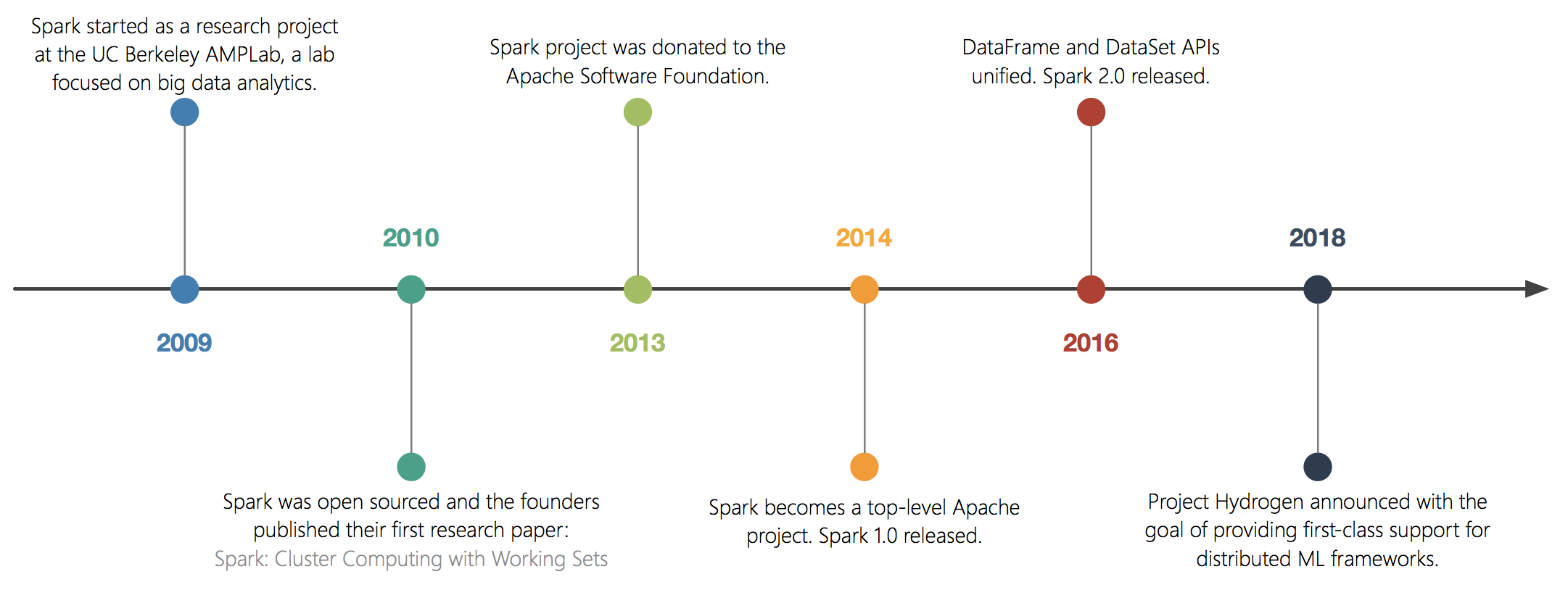
Ecosystem

Spark SQL
Spark SQL is a Spark library for structured data processing. Spark SQL brings native SQL support to Spark as well as the notion of DataFrames. Information workers are free to use either interface or toggle between both while the underlying execution engine remains the same.
Spark Streaming
Spark Streaming can ingest and process live streams of data at scale. Since Spark Streaming is an extension of the core Spark API, streaming jobs can be expressed in the same manner as writing a batch query.
MLlib (Machine Learning)
Spark's Machine Learning Library (MLlib) provides a common set of algorithms (classification, regression, clustering, etc) and utilities (feature transformations, ML pipeline construction, hyper-parameter tuning, ML persistence, etc) to perform machine learning tasks at scale.
GraphX (Graph Processing)
GraphX is a Spark library that allows users to build, transform and query graph structures with properties attached to each vertex (aka node) and edge (aka relationship).
Spark Core
Spark Core is the underlying execution engine that all other functionality is built on top of. Spark Core provides basic functionalities such as task, scheduling, memory management, fault recovery, etc as well as Spark's primary data abstraction - Resilient Distributed Datasets (RDDs).
Apache Spark vs. MapReduce
TL;DR - Spark is faster and easier to use.
MapReduce (introduced back in 2004), a mature software framework, has been the mainstay programming model for large-scale data processing. While MapReduce is great for single-pass computations, it is inefficient when multiple passes of data are required. While not a big deal for batch processing, MapReduce can be painfully slow in scenarios which require the sharing of intermediate results. This is quite common for certain classes of applications such as interactive ad-hoc queries, machine learning, real-time streaming, etc.
MapReduce, as was the case for many frameworks at the time, would need to write an interim state to disk (i.e. a distributed file system) in order to reuse data between computations. Each iteration would incur a significant performance overhead with each pass due to data replication, data serialisation, disk I/O, etc, consuming a substantial amount of the overall execution time.

In contrast, Spark's programming model revolves around Resilient Distributed Datasets (RDDs), an abstraction of distributed memory (in addition to distributed disk), making the framework an order of magnitude faster for algorithms that are iterative in nature.
In addition to being performant, Spark provides high-level operators (Transformations and Actions) that can be expressed in a number of language APIs (Java, Scala, Python, SQL, and R), making Spark easy to use in comparison to MapReduce which can get quite verbose as developers are required to write low-level code.
MapReduce (Java)
Source: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v1.0
// Word Count Example - MapReduce (Java)
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} Spark (Python)
Source: https://spark.apache.org/examples.html
# Word Count Example - Spark (Python)
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")Spark Operations
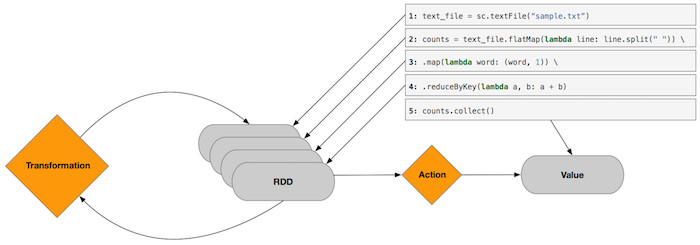
Spark supports two types of operations:
Transformations
Transformations take an input, perform some type of manipulation (e.g. map, filter, sample, distinct), and produce an output.
- Since data structures within Spark are immutable (i.e. unable to be changed once created), the output of a transformation is not the results themselves but a new (transformed) data abstraction (i.e. RDD or DataFrame).
- Transformations are lazy (i.e. Spark will not compute the results until an action requires the results to be returned). This allows Spark to optimise the physical execution plan right at the last minute to run as efficiently as possible.
Actions
Actions trigger the execution of transformations and materialise the results (e.g. count, min, max, collect).
Below is the example Word Count application deconstructed, to visualise the differences between Transformations and Actions.
Code
text_file = sc.textFile("sample.txt")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.collect()Input and Output

Spark Internals
Getting Started
The quickest and easiest way to get started is to simply download the latest release of Apache Spark on your local machine and interact with Spark via the shell.
- Navigate to https://spark.apache.org/downloads.html
- Click to jump to the list of available mirror sites.
- Click the suggested download link.

Once downloaded, extract the zipped contents, navigate to the spark directory, and start the spark shell.
For example:
- cd ~/Downloads/spark-2.3.1-bin-hadoop2.7
- bin/pyspark
Note: In this example I have started the Spark shell in Python, alternatively, you can use Scala by typing bin/spark-shell

In terms of next steps, check out Apache's Quick Start which contains some sample code for both Scala and Python. In a subsequent post, I will cover how you can tap into Spark-as-a-Service in the cloud using Azure Databricks (stay tuned).