Azure Synapse Link for Dataverse
/Contents
1. What is Azure Synapse Link?
First thing to note is that Azure Synapse Link in and of itself, is not a product or feature unless we are referring to a specific implementation, of which there are currently three versions available:
Conceptually speaking though, the advertised benefits between each of these instances are consistent:
Continuous export of data from an operational data store (Azure Cosmos DB, Dataverse, or SQL).
Data made accessible for near real-time analytics via integration with Azure Synapse Analytics (*).
Minimum impact on source systems as there is a continuous replication of incremental changes.
Reduced complexity, as there are no ETL jobs to manage, this is all handled by the service.
(*) Worth noting that Azure Synapse Analytics does not necessarily mean Azure SQL Data Warehouse (now known as Dedicated SQL Pools), while Azure Synapse Analytics has a long history in meeting the needs of the enterprise data warehouse, it is an end-to-end analytical platform (data integration, data engineering, data warehousing) with multiple analytics engines. With that in mind, and in the context of Synapse Link, the key takeaway is that operational data is made available for analytical workloads via Azure Synapse Analytics in some shape or form (e.g. Serverless SQL, Dedicated SQL, Apache Spark, etc). See table below for a high-level overview of each service.
| Service | Status | Source | Destination | Query Engine |
|---|---|---|---|---|
| Azure Synapse Link for Azure Cosmos DB | GA (Mar 2021) | Azure Cosmos DB (Transactional Store) | Azure Cosmos DB (Analytical Store) |
Synapse Spark, Synapse SQL (serverless) |
| Azure Synapse Link for Dataverse | GA (Nov 2021) | Dataverse | Azure Data Lake Storage Gen2 | Synapse Spark, Synapse SQL (serverless) |
| Azure Synapse Link for SQL | Preview (May 2022) | Azure SQL Database, SQL Server 2022 |
Azure Synapse Analytics Dedicated SQL Pools | Synapse SQL (dedicated) |
2. What is Microsoft Dataverse?
(formerly known as Common Data Service)Dataverse is a cloud-based storage service, fully managed and maintained by Microsoft, that enables customers to securely store and manage business application data. Dataverse comes out of the box with a standard set of tables that cover typical business scenarios, but you can also create custom tables specific to your organization. Note: Dynamics 365 applications such as Dynamics 365 Sales, Dynamics 365 Customer Service, or Dynamics 365 Talent use Dataverse to store and secure the data they use.
3. What is Azure Synapse Link for Dataverse?
(formerly known as Export to Data Lake)Azure Synapse Link for Dataverse provides a continuous pipeline of data from Dataverse to Azure Synapse Analytics or Azure Data Lake Storage Gen2. Once the link is established, the service will export all the initial data as well as sync any incremental changes, enabling customers to glean near real-time insights from data sourced from the Microsoft Dataverse service.
Link or unlink to Azure Synapse Analytics and/or Azure Data Lake Storage Gen2.
Continuous replication of tables (both standard and custom tables).
Any data or metadata changes in Dataverse are automatically pushed to the Azure Synapse Analytics metastore and Azure Data Lake (push, not pull).

In the context of Azure Synapse Link for Dataverse, configuring the destination to be Azure Synapse Analytics (as opposed to simply Azure Data Lake Storage Gen2) equally results in the data being stored in an Azure Data Lake Storage Gen2 account, but has the added benefit of CSV-backed table objects being created and maintained by the service, that are visible to users via the Azure Synapse workspace and can be queried using Synapse analytical runtimes such as the serverless SQL endpoint.
4. History
Back in 2016, Microsoft released an add-on called the Data Export Service (DES) on Microsoft AppSource, this solution provided customers the ability to replicate Dynamics 365 data (aka Dataverse data) to an Azure SQL Database within a customer-owned Azure subscription. This was eventually superseded by Export to Data Lake, which was later renamed to Synapse Link for Dataverse. By November 2021, Synapse Link for Dataverse reached GA status, shortly after, the product team announced the deprecation of the Data Export Service. The Data Export Service is planned to continue to work and be fully supported until it reaches end-of-support and end-of-life in November 2022.

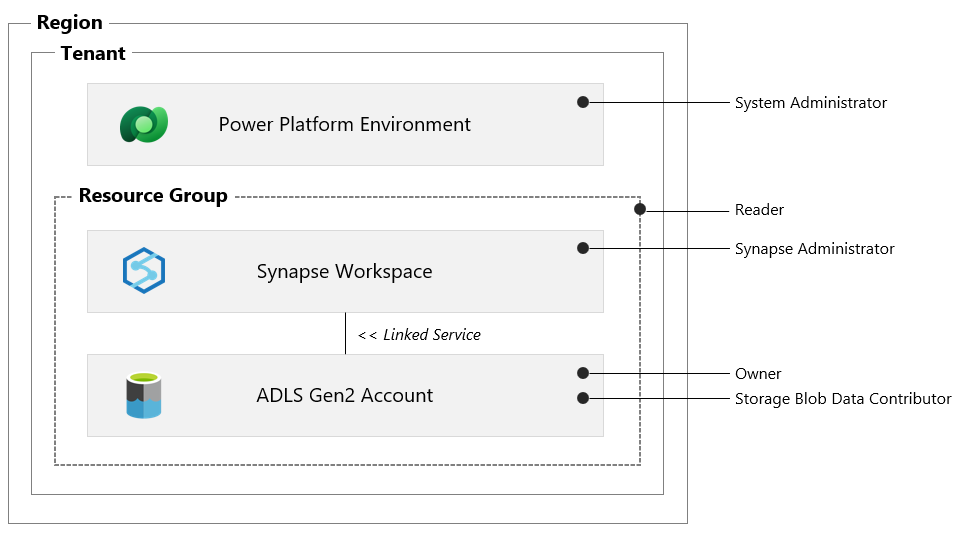
5. Prerequisites
Before we can establish a link between data in the Dataverse and Azure Synapse Analytics, there are a number of prerequisites that need to be met, please see details and summary graphic below.
Azure Data Lake Storage Gen2
You must have an Azure Data Lake Storage Gen2 account.
You must have Owner and Storage Blob Data Contributor role access.
You must enable Hierarchical namespace.
It is recommended that replication is set to Read-Access Geo-Redundant Storage (RA-GRS).
Azure Synapse Analytics
You must have a Synapse workspace.
You must have Synapse Administrator role access within Synapse Studio.
You must provision the Synapse workspace in the same region as your Azure Data Lake Storage Gen2 account.
You must provision the Synapse workspace in the same resource group as your Azure Data Lake Storage Gen2 account.
You must add the storage account as a linked service within Synapse Studio.
Dataverse
The Azure Data Lake Storage Gen2 account and Synapse workspace must be created in the same Azure Active Directory (Azure AD) tenant as your Power Apps tenant.
The Azure Data Lake Storage Gen2 account and Synapse workspace must be created in the same Azure Active Directory (Azure AD) region as your Power Apps environment.
You must have the Dataverse System Administrator security role.
Note: Only tables that have change tracking enabled can be exported.
6. Connect Dataverse to Synapse workspace
Create a new link
Sign in to https://make.powerapps.com and select your preferred environment.
On the left navigation pane, expand the Dataverse menu.
Select Azure Synapse Link.
On the command bar, click New link.
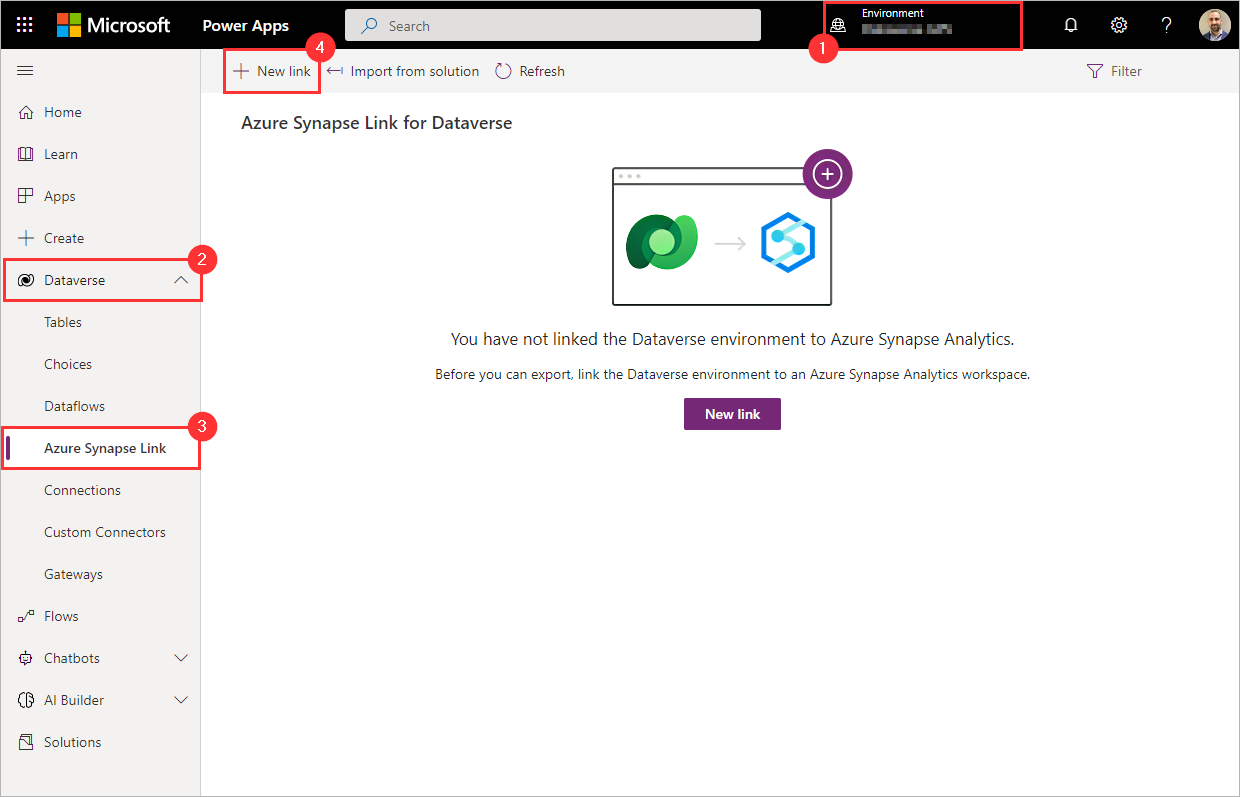
Select your Azure Synapse Analytics workspace
Select the checkbox to Connect to your Azure Synapse Analytics workspace.
Set the Subscription.
Set the Resource group.
Set the Workspace name.
Set the Storage account.
Click Next.

Add Tables
Select the tables that you want to export.
Click Save.

7. Role Assignments
After clicking save, there are a number of HTTP requests made from the browser, predominantly to two API services:
management.azure.com (to perform role assignments)
athenawebservice.{gateway}.powerapps.com (to establish the Synapse link)
Note: If you are interested in the detail, open up DevTools by hitting F12 on your keyboard (using Edge or Chrome), and monitor the network traffic immediately after clicking Save.
In summary, the below high-level actions can be observed in the following order:
6 x role assignments at the Azure resource level (1 x Synapse Workspace, 5 x Storage Account)
2 x containers created within the storage account (dataverse-{envName} and power-platform-dataflows)
5 x role assignments at the container level (4 x dataverse-{envName}, 1 x power-platform-dataflows)
Synapse Link created (e.g. Entities, AppendOnlyMode=True/False, PartitionStrategy=Month/Year, etc)
The graphic below provides a high-level overview of the role assignments performed for each resource. These can be validated by navigating to the appropriate access control pane for each resource.

8. Lake Database
To understand what has materialised within Synapse, navigate to your Synapse workspace, open the Data hub, and expand Lake database. You will find that the following has been created:
1 x Lake Database.
2 x Tables per Entity (Near Real-Time and Snapshot).
A standard set of 5 x tables for Dataverse choice labels (see Access choice labels from Azure Synapse Link for Dataverse for more information).

Using a tool such as Azure Data Studio, we can unpack the tables to understand them further by viewing the SQL create statements.
Near Real-Time Data
CREATE EXTERNAL TABLE [dbo].[account]
(
EXPLICITLY_DEFINED_SCHEMA
)
WITH (
DATA_SOURCE = [datasource_GUID],
LOCATION = N'*.csv',
FILE_FORMAT = [delimitedtextGUID]
)To find the details behind external resources such as DATA_SOURCE and FILE_FORMAT, we can query system views such as sys.external_data_sources and sys.external_file_formats.
In this example:
DATA_SOURCE
LOCATION = https://{storageAccount}.dfs.core.windows.net/dataverse-{envName}/account/
FILE_FORMAT
FORMAT_TYPE = DELIMITEDTEXT
FIELD_TERMINATOR = ',',
STRING_DELIMITER = '"',
FIRST_ROW = 1,
USE_TYPE_DEFAULT = False,
ENCODING = 'UTF8'
Snapshot Data
CREATE VIEW [dbo].[account_partitioned] AS
(
SELECT *
FROM
OPENROWSET(
BULK (
N'https:///account/Snapshot/2022-06_1658922978/*.csv'
,N'https:///account/Snapshot/2022-07_1658922978/*.csv'
),
FORMAT = 'csv',
FIELDTERMINATOR = ',',
FIELDQUOTE = '"',
)
WITH (EXPLICITY_DEFINED_SCHEMA)
AS T1
)As can be seen in the summary graphic below, the near real-time table is backed by CSV files directly beneath the entity folder (e.g. account), whereas the snapshot table is backed by CSV files beneath specific folder paths (e.g. account/Snapshot/{snapshotFolder}).

9. Folders and Files
Navigating to the underlying storage account, we can see the exported data files (CSV), corresponding metadata (model.json), and folder structure used to isolate read-only snapshots.
model.json
The metadata file (model.json) in a Common Data Model folder which describes the exported data.
Contains a list of exported entities (aka tables).
Each entity is described with a name, description, annotations, and attributes (schema).
The model.json file is updated on a regular interval to point to the relevant snapshot files.
Snapshot folder and files
A snapshot folder is included with each table exported to the data lake.
Snapshots provide a read-only copy of data that is updated at regular intervals (every hour).
This ensures data consumers can reliably consume data in the lake.
Data files
Changes in the Dataverse are continuously pushed to the corresponding CSV files.
By default, files are partitioned by month based on the createdOn value in each row. The partition strategy can be changed to year within the advanced configuration settings.
By default, the service will perform an in-place update (UPSERT) of the incremental changes. The update strategy can be changed to append only via the advanced configuration settings.

10. Incremental Change
So what happens when a CUD (Create, Update, or Delete) operation occurs on a synced table? Note: The following is based on a default partition and update strategy (i.e. monthly and in-place).
In less than 5 minutes:
Changes are written to the relevant CSV file(s) that sit directly beneath the entity folder.
These particular files underpin our near real-time table in the lake database (e.g. account).
For example, if the CUD operations occurred against data with createdOn values in July 2022, the file that would be updated would be 2022-07.csv.
In less than 1 hour:
New snapshot CSV file(s) will be created and persisted beneath the Snapshot folder for the updated partitions.
The model.json file will be updated to reflect the new partition location(s) (e.g. path: entities.account.partitions.2022-07.location).
The definition of the lake database table that refers to the snapshot files will be updated with the new location(s).
Illustrated example below where the snapshot files are updated on the 56th minute of every hour. Note: In this example, it took approximately 16 minutes for the lake database table based on the read-only snapshot files to catch-up with the changes that were nearly immediately reflected in the lake database table based on the near real-time files. That said, if the CUD operation were to occur just after the 56th minute (since this is when the hourly snapshot files are generated), this gap can be as long as 1 hour.

11. Advanced Configuration
When adding tables to be in scope, you can alter the default settings that will determine how data will be exported and ultimately written to the data lake. These additional options can be revealed by toggling on the advanced configuration.

In-place updates vs append-only writes
For tables where createdOn is available, the default setting is in-place update (AppendOnlyMode = False).
For tables where createdOn is not available, the default setting is append-only writes (AppendOnlyMode = True).
Using the advanced configuration settings, append-only mode can be enabled, this is available as a per table setting.
If append-only is enabled, the partition strategy defaults to year.

The table below describes how rows are handled in the lake against CUD operations for each of the data write strategies.
| Event | In-place update | Append-only |
|---|---|---|
| CREATE | Row is inserted | Row is added to the end |
| UPDATE | Row is replaced | Row is added to the end |
| DELETE | Row is removed | Row is added to the end with isDeleted column = True |
Guidance on when to use which option:
In-place updates: If you are planning to query the data directly from the data lake and only require the current state (as history will not be preserved).
Append-only: If you require historical changes to be preserved. If you are not planning to query the data directly and would like to incrementally copy changes to another target.
Data Partitioning
For tables where createdOn is available, the tables are partitioned by time (default is Month).
For tables where createdOn is not available, the tables are partitioned every five million records.
This is a per table setting.
For high data volumes, it is recommended to partition by month as this will result in smaller files (compared to partition by year).

12. Incremental Update Folder Structure (preview)
The incremental update folder structure feature (currently available in preview), creates a series of timestamped folders containing only the changes to the dataverse data that occurred during the user-specified time interval. For example. if the time interval is set to 15 minutes, the service will create incremental update folders every 15 minutes that will capture changes that occurred within the time interval.
Creates a separate timestamped folder for the updates that occur within a user-specified time interval.
Each folder is written in the Common Data Model format.
When enabled, all tables in the link are set to append-only mode with a yearly partition strategy.
The minimum time interval is 15 minutes.
Timestamp and table folders are only created when there is a data update within the user-specified time interval.
Near real-time data view is not supported when the incremental update folder feature is enabled. Note: This is a known issue, the near real-time table will still appear in the lake database but will not function as expected.

When this feature is enabled, the top-level folder structure changes to timestamp folders that are aligned to the user specified time-interval. For example, if you have a constant stream of changes happening in one of the Dataverse tables that are included in the scope of the link, and the time-interval is set to 15 minutes, expect to see a new timestamp folder every 15 minutes. Beneath the timestamp folder you will find a folder for each synced entity (table) containing the yearly partitioned CSV files that are set to append-only mode.

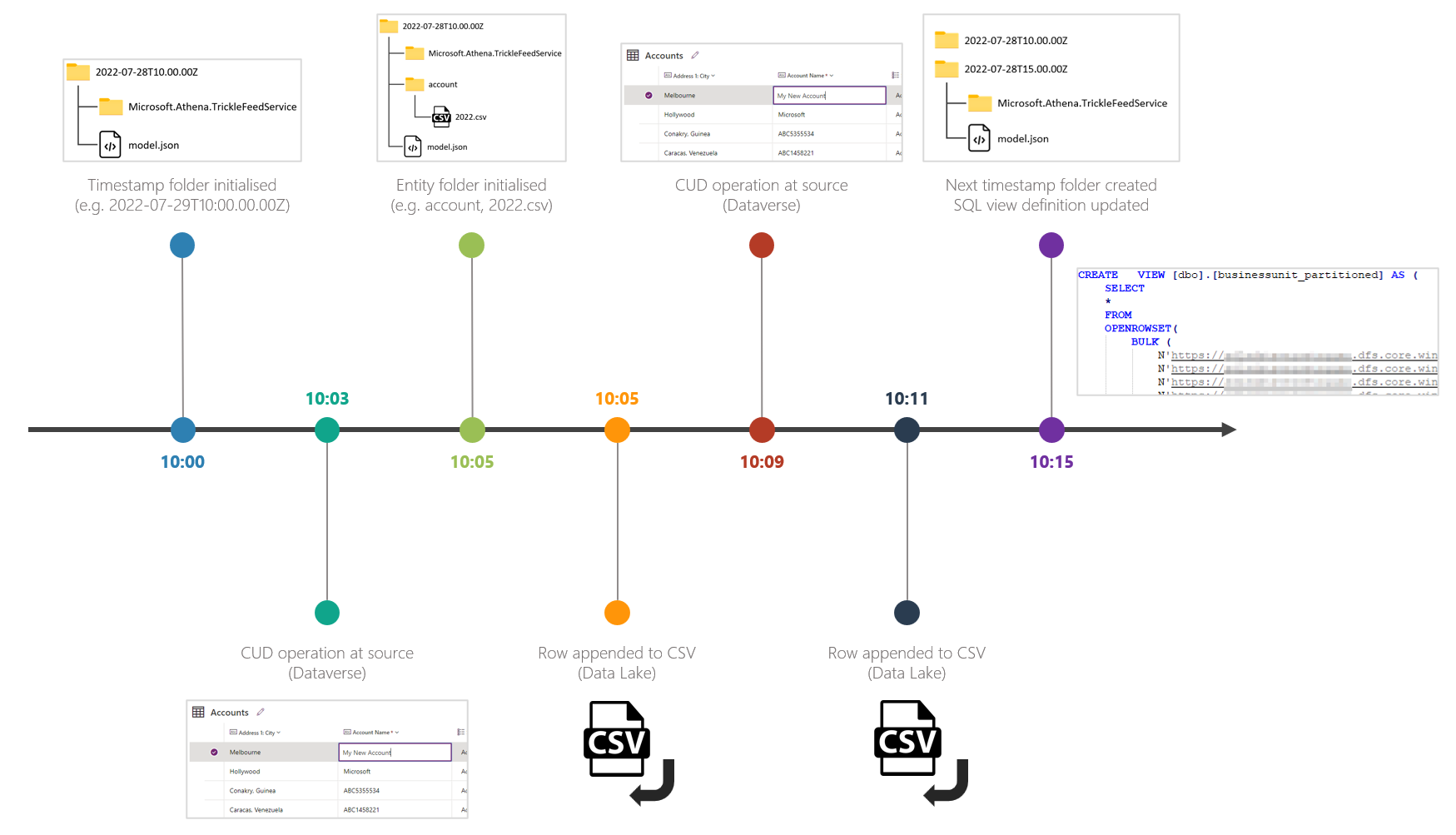
Based on my testing, the high-level flow of activity appears to be the following:
Timestamp folder created (e.g. 2022-07-28T10.00.00Z).
Change occurs at source (e.g. update a row).
The first change that is detected causes the entity sub-folder to be created (e.g. account) and the CSV file to be initialised (e.g. 2022.csv).
The data is appended to the end of the CSV file.
Steps 2 and 4 (change at source AND data being appended) continue to repeat until the time interval closes (e.g. 15 minutes).
Once the next time interval arrives, the next timestamp folder is created (e.g. 2022-07-28T10.15.00Z).
The lake database table definition for the view (e.g. account_partitioned) is updated to include the closed timestamp folder path in the OPENROWSET function (e.g. 'https://{storageAccount}.dfs.core.windows.net/dataverse-{envName}/2022-07-28T10.00.00Z/account/*.csv').
Note:
As mentioned in the graphic above, even though the next timestamp folder has been created, it will remain empty of entity folders and CSV files until the next change is detected. At which point, steps 2 onwards repeat.
Even though a CSV file may exist in the latest timestamp folder, the view will not reference that path until that window has closed. This means that the SQL view may be up to 15 minutes behind.
13. Analyze with Azure Synapse Analytics
Once Azure Synapse Link has been switched on to continuously export Microsoft Dataverse data and the corresponding metadata, users have several options in how to query and analyze the data downstream.
Serverless SQL
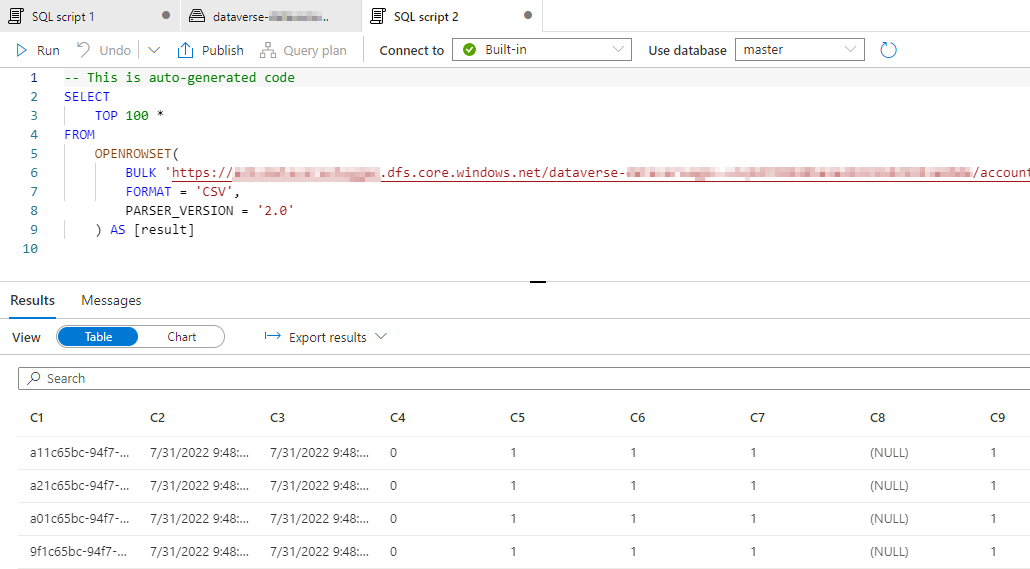
Serverless SQL is a query service that enables users to run SQL on files placed in Azure Storage. Since Synapse Link for Dataverse exports the data to the data lake as CSV files and creates a logical abstraction via a lake database, we can query this data either directly using the OPENROWSET function or indirectly via the tables and views.
The example below shows how to query the near real-time data by right-clicking on the table, and selecting New SQL script > Select TOP 100 rows.

Similarly, we can navigate directly to the files on the data lake. In this example, the auto-generated SQL will use the OPENROWSET function to query the CSV file.

While querying the files this way will return data, it will be missing schema information (e.g. column names, column types). This is one of the benefits of using the lake database tables where the metadata is maintained by the Synapse Link service.
Apache Spark
In addition to SQL, Azure Synapse Analytics offers alternative analytics engines optimized for different workloads, including Apache Spark - a big data compute engine. The example below shows how to right-click on a Synapse Link for Dataverse table and use the New notebook action to auto-generate code that will load Microsoft Dataverse data into an Apache Spark DataFrame.

Data flows
For those looking for a code-free data transformation authoring experience, Data flows are visually designed and allow data engineers to develop data transformation logic without writing code. Using the Workspace DB connector, you can set the source of a data flow to a Dataverse database and table. Once the data flow has been constructed by optionally adding other transformation steps and the addition of a sink, Synapse pipelines can be used to orchestrate the execution a data flow activity.

Alternatively, since the exported data is adhering to the Common Data Model (CDM) format, the data flow source step can be set to the Inline connector with the Common Data Model dataset type. Note: This method references metadata contained within the model.json file which will refer to the read-only snapshot locations. In which case, the data can be up to one hour behind since snapshots are taken every hour.

Power BI
Lastly, since Power BI can connect to Azure Synapse Analytics, we can query the Microsoft Dataverse data using the lake database tables. Example below connecting to the serverless SQL endpoint and loading the account table into Power BI.
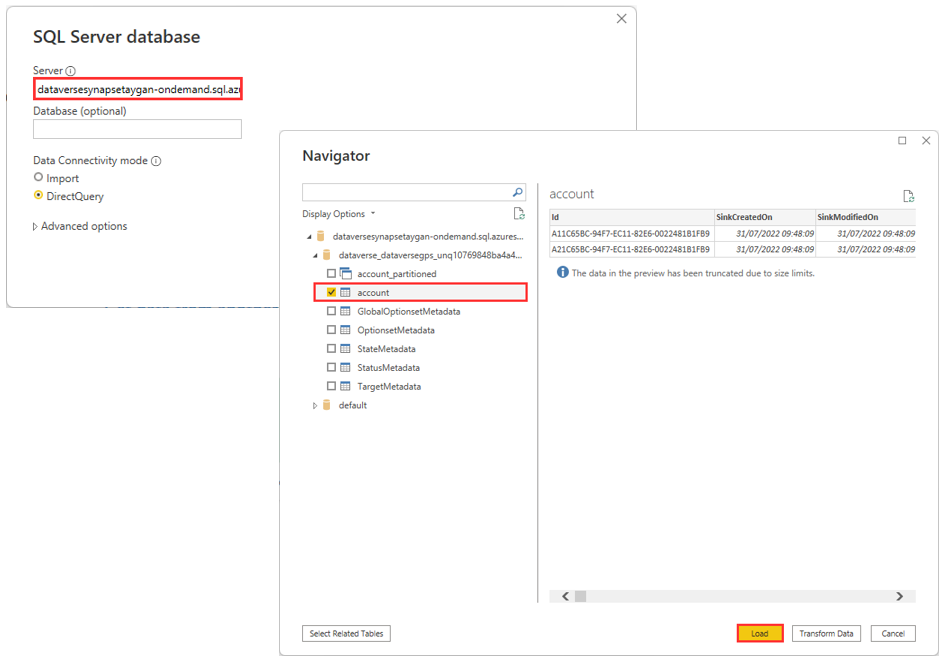
14. Architecture
For those interested in understanding what is happening behind the scenes, the product team discuss the high-level architecture underpinning the Synapse Link for Dataverse service during the Microsoft Business Application Summit (June 2019).
In summary:
Synapse Link for Dataverse service subscribes to CUD events for entities (aka tables) that are in scope.
Microsoft Dataverse (formerly known as the Common Data Service) writes to the Service Bus whenever a CREATE/UPDATE/DELETE operation occurs (i.e. messages are pushed, not pulled).
The Trickle Feed logic reads from the Service Bus and writes the data to the Azure Data Lake Storage Gen2 account.
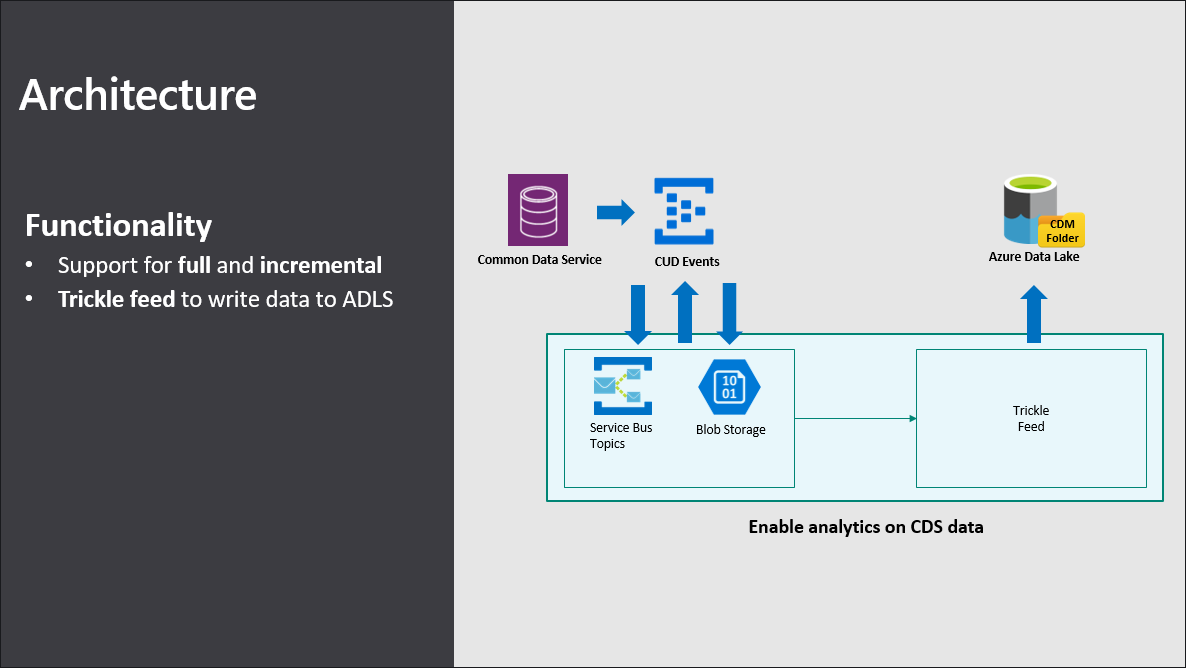
While modern data formats such as Parquet or Delta Lake may be supported in the future, the service currently writes to CSV which is typically not able to handle in-place updates. That said and as mentioned by Mudit Mittal (Principal Engineering Manager @ Microsoft) during the MBAS session, there is some in-built intelligence via an internal index management system which tells Synapse Link where inside the CSV file does the service need to go and update a record (as opposed to rewriting the entire file each time).